目标:
识别学生手写的选择题,判断题答案
识别结果只需要 A B C D 四个大写字母,和判断题的 勾和叉 。使用现有的公共平台,学生若是将B写开一点会识别成13等奇怪的问题。后期又增加了一个涂改识别,若是写错了,学生将A完全涂黑,作为第7种结果。
分析:
需要识别的结果很少,而且特征差异明显,准备自己实现。
opencv对多平台支持比较友好,有基于java的实现,而且通过Mat指针的方式,效率也不低。
实现:
第一步、预演
核心方法K值相似的方法 用到了 CvKNearest 类。
首先是 cvKNearest.train(trainData, response); 训练模型,这个加载很快。
然后将需要识别的图片cvKNearest.find_nearest(mat, 3, result, neighborResponses, dists);查找就近样本。
opencv 提供了一个letter-recognition.data,里面每一行是字母和特征描述。
用前三分之二的数据训练,验证后三分之一,可以跑通。
问题是 这个数据集的 16个特征值没有详细说明如何制作的,没法用,所以还得自己收集数据集。
第二步、收集数据集
网上找不到,还好只需要6个字母,找同事10人每人写了3个A,3个B,3个C。。。拿到了每个字母30个样本图片。
将字母切边,统一缩放到20x20的大小。其实样本比较少效果比较差,后面再回来对每个样本,左旋转10度,右旋转10度,顶部透视左倾斜,顶部透视右倾斜。这样一张原图,再变4张图片出来,一共就有150个图片了。这时候效果就不错了。
第三步、确认特征值
尝试了两种特征值,第一种是 模仿上面的数据集,计算每一列有像素的数量,每一行有像素的数量,左边10列的像素值
,右边10列的像素值,上边的,下边的,左边减去右边的,上边减去下边的。
第二种是直接20*20的 400个像素位置直接放进去。测试了,是第二种效果好。
第四步、切图
现在可以训练出模型了,只要拿着一张图片去测试就可以得到结果,但是学生的作答图片是一大张,而且会写多个字母。
所以使用opencv先进行预处理,先膨胀,再腐蚀,然后寻找cany边缘,然后找到最小矩形轮廓。
然后截出每个单字母,做到这里才发现切图是一个难点,能正确的切出每个字母就已经成功了一半了。
第五步、反馈调整数据集
上面做完后,可以正常识别了,但是还是会遇到识别出错的情况。这个时候,自己研发的优势就体现出来了,可以方便的将这个识别错误的图片增加到样本中。重新训练,这样收集了几个奇怪的写法后,基本上没有问题了。
效果图如下
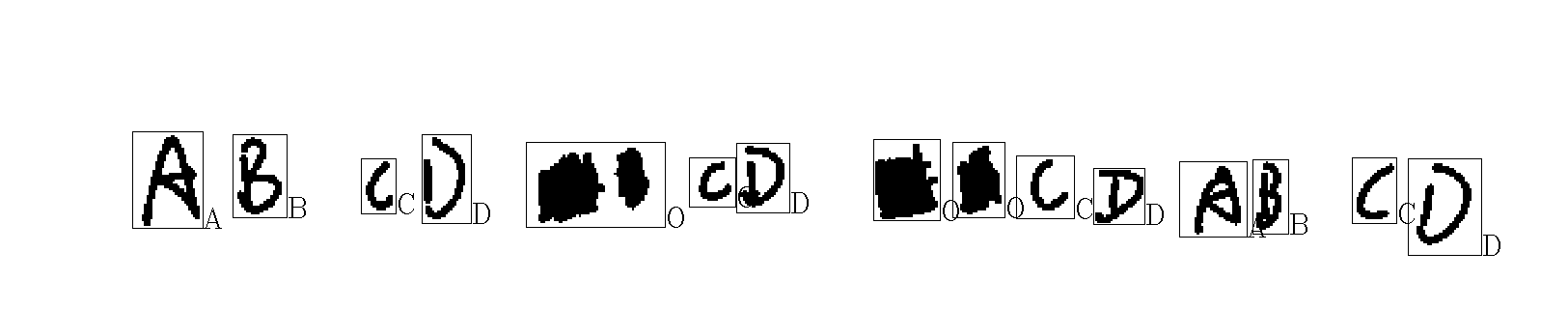
总结:
整个耗时3天,总结下来,难点还是在切图,如果连笔了,还没有很好的办法区分。思路大概应该是设置一个高宽比阈值,超过了计算像素投影,在最低像素点切开。然后是数据集,使用了后来优化的1变5后,很明显,但是需要涵盖到各种写法所以后面的收集反馈也比较重要,需要注意的是这里不用过多增加,针对不同写法笔法进行增加就可以。
基于k值相似方法的识别速度也很快,在100ms左右,成功率在95%左右。